Performance Measurement Glossary: Key Terms
Definition of Leading indicator
What is a leading indicator?
A leading indicator is a measurable signal that forecasts future performance, highlighting potential problems or opportunities before they materialize in project outcomes.
In software project management, leading indicators detect patterns that predict schedule delays, quality issues, or resource constraints weeks before they appear. Rising code review backlog signals future velocity problems; increasing work-in-progress warns of upcoming bottlenecks; growing technical debt forecasts quality degradation.
The value lies in the 2-4 weeks of advance warning these metrics provide, transforming project management from reactive firefighting into proactive risk mitigation.
How is a leading indicator different from a lagging indicator?
Leading and lagging indicators describe different kinds of signals about project health. Understanding how they differ helps leaders choose the right metrics for both early warning and accountability:
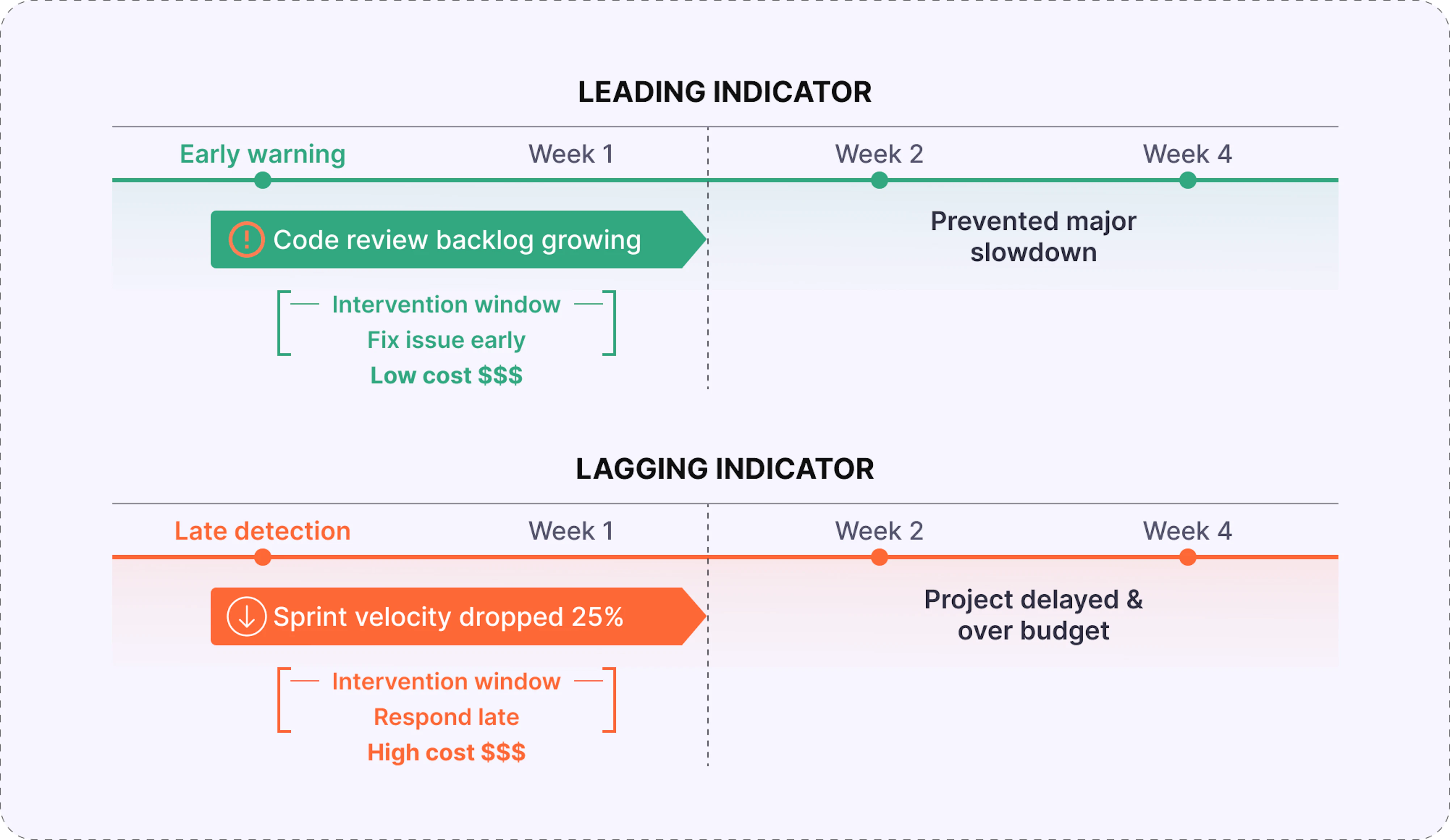
Leading indicators predict future outcomes by measuring activities that drive performance, enabling teams to intervene before problems fully develop. For example, a jump in work-in-progress from 12 to 18 tasks warns of upcoming bottlenecks before throughput drops.
Lagging indicators, by contrast, measure outcomes that have already occurred and confirm success or failure after the fact – essential for accountability, but too late for prevention. A sprint that misses its deadline by three days reveals a delivery problem only once customer impact is unavoidable.
The real value comes from using both together: leading indicators guide real-time decisions, while lagging indicators validate whether those interventions worked. Teams that track only lagging metrics discover problems after options narrow and costs rise, while those monitoring leading signals can adjust early enough to protect timelines, quality, and budget.
Why are leading indicators important?
Leading indicators change when teams see problems and the options they still have to respond. Instead of discovering issues after deadlines slip or customers are impacted, teams gain a time window where solutions are simpler, cheaper, and less disruptive.
- Lower cost of fixing problems
Catching issues early is dramatically cheaper than resolving them once they affect production or budgets. A code review backlog spotted three weeks ahead can be handled by reallocating reviewers; ignored, the same signal becomes a release delay requiring overtime or painful descoping. - Preserved strategic and delivery options
Early signals keep more responses available. If technical debt trends point to quality issues four weeks out, teams can refactor gradually or trim scope; if the first signal is a production incident spike, remaining options are far more disruptive. - Protection of team health and sustainability
Leading indicators expose unsustainable load before burnout hits. Capacity overload, rising overtime, or growing unplanned work appear as early signals, giving managers time to rebalance work or renegotiate timelines before morale and productivity erode. - Stronger trust and clearer communication with stakeholders
Early, quantified signals support more credible conversations with executives and clients. Instead of reporting "we missed the deadline," teams can say "we're trending 10% over capacity; we recommend descoping Feature X or extending by two weeks," positioning the team as a reliable, forward-looking partner.
Teams that systematically track leading indicators benefit on all four fronts at once: they spend less on late fixes, retain more strategic flexibility, protect their people, and communicate with stakeholders from a position of informed control rather than damage control.
What are common examples of leading indicators for software teams?
Software teams track leading indicators across four categories to stay ahead of delivery risks, quality issues, capacity overload, and process breakdowns.
Delivery and velocity predictors
- Work-in-progress trends: taking on 15 tasks when 10 is sustainable typically causes a velocity drop 2-3 weeks later
- Cycle time variance: inconsistent task completion times signal process instability, leading to missed deadlines
- Pull request aging: PRs unreviewed for 3+ days predict integration delays
Quality and technical health indicators
- Declining code review thoroughness: fewer comments per PR or rushed reviews predict quality escapes 1-2 sprints later
- Technical debt accumulation: debt growing 15% monthly while velocity stays constant, forecasts defect rate spikes 8-12 weeks later
- Test coverage trending downward: forecasts production incidents 4-6 weeks out
Team collaboration and capacity signals
- Communication frequency dropping 30%: predicts coordination failures 2-3 weeks later
- Overtime hours trending upward: signals burnout risk 4-8 weeks ahead
- Unplanned work rising above 40% of capacity: makes sprint goals unreachable before failures occur
Process and financial indicators
- Blocked tasks stuck 3+ days: predict workflow breakdowns
- Scope creep mid-sprint: unplanned story points added predict budget overruns 4-6 weeks before financial impact appears
- Vendor response time degrading: signals integration delays before they block critical paths
Effective teams monitor 8-12 specific leading indicators spread across these four categories, each one aligned with their highest‑impact risks.
How do you choose effective leading indicators for your projects?
Selecting the right leading indicators requires focusing on your highest risks while ensuring they're predictive, actionable, and measurable. Here is a step‑by‑step approach you can use to choose and refine them:
Step 1. Start with the highest-impact risks
Identify 3-5 critical risks and match indicators to them directly. For a launch risk, track sprint velocity trends and blocked task age; for quality concerns, monitor code review depth and test coverage.
Step 2. Ensure indicators are predictive and actionable
Validate through historical data that when the indicator changed, the predicted outcome followed 2-4 weeks later. Only track signals where intervention is possible: "growing code review backlog" lets you reallocate reviewers; external market shifts do not.
Step 3. Confirm measurability and balance
Indicators must pull from existing systems automatically, with no manual logging. Aim for roughly 60% leading indicators and 40% lagging to maintain balance without overwhelming teams.
Step 4. Keep it manageable
Monitor 8-12 indicators maximum. Test hypotheses for 2-3 months: Did they provide advance warning? Were interventions effective? Drop indicators that don’t add value.
Teams that align indicators to specific risks, validate their predictive power, and continuously refine their set build early warning systems that prevent most project crises. With the right indicators selected, Enji makes tracking and acting on them straightforward and automatic.
How does Enji help track and act on leading indicators?
To turn leading indicators into real outcomes, teams need help in three areas: understanding why signals change, getting timely alerts, and validating that interventions work. Enji supports each of these steps:
1. Root cause analysis and recommendations
🟣 Enji automatically connects leading indicator changes to project events, eliminating hours of manual investigation.
Project Narrative™ technology correlates signals with context. For example, linking a 30% velocity drop to scope expansion, production incident firefighting, and developer vacations happening simultaneously.
PM Agenttranslates signals into actionable recommendations, such as identifying a code review backlog of 25 PRs against a normal baseline of 8, diagnosing the cause, and suggesting a specific redistribution of reviews with an expected timeline to restore velocity.
2. Automated tracking and proactive alerts
🟣 Enji eliminates hours of weekly manual monitoring by automatically tracking technical and capacity indicators in real time.
Team Code Metrics and Individual Code Metrics cover code review velocity, work-in-progress trends, cycle time variance, and technical debt accumulation, while Enlightening Worklogs monitor overtime, context switching, and unplanned work.
Routine Alerts notify managers when thresholds are crossed, such as when a code review backlog or work-in-progress count exceeds defined limits, so issues are surfaced before they compound.
3. Portfolio patterns and validation
🟣 Enji reveals organizational patterns across projects and validates which interventions actually work.
Summarizer creates portfolio health reports that surface cross-project patterns, such as the proportion of projects with high overtime that later missed deadlines, enabling targeted process improvements.
Enji also closes the learning loop by tracking both early warnings and outcomes, confirming whether interventions such as adding reviewer capacity actually maintained velocity at the expected level.
Key Takeaways
- Leading indicators are forward-looking signals that predict future performance before results materialize, enabling proactive intervention, unlike lagging indicators that confirm outcomes after they occur.
- Leading indicators reduce problem-solving costs through early detection, preserve strategic options, protect team morale, and create a competitive advantage.
- Common examples include work-in-progress trends, code review velocity, technical debt accumulation, cycle time variance, overtime patterns, and test coverage trends.
- Choose effective indicators by aligning with your biggest risks, validating predictive power, ensuring actionability, and maintaining a focused portfolio.
- Enji enables leading indicator management through automated tracking, proactive alerts, root cause analysis, portfolio pattern recognition, and actionable recommendations.

Last updated in March 2026