Почему фаундерам, работающим с вайб-кодингом, нужен "санитарный слой" перед Series A


Анализ с помощью ИИ
Получите аналитику на основе ИИ для этой статьи Enji:
Скорость, которая вас продает, и код, который вас подводит
Вайб-кодинг действительно работает – и это не предмет дискуссии. Если вы фаундер и уже использовали ИИ, чтобы за несколько недель пройти путь от идеи до работающего продукта, вы сами знаете, насколько это реально: то, на что раньше уходили месяцы и целые команды, сегодня умещается в недели работы одного человека. Вопрос не в самой скорости, а в том, что она неизбежно оставляет за собой.
ИИ-ассистированная разработка исключительно хорошо справляется с тем, чтобы код работал: проходил демонстрацию, закрывал базовые тест-кейсы, выпускал функции в темпе, который несколько лет назад потребовал бы целой команды. Но у нее есть слепое пятно, и оно принципиальное. Безопасность, архитектурная целостность, устойчивость к условиям, которых в исходном запросе не было – все это остается за кадром не потому, что ИИ плохо справляется, а потому что он решает ровно ту задачу, которую ему поставили. Разрыв между "работает" и "выдержит" – вот где живет большая часть рисков.
Я раз за разом наблюдаю одну и ту же картину у компаний на ранней стадии, которые приходят к нам после активной генерации кода. Продукт выглядит впечатляюще, демо впечатляюще выглядит, а потом кто-то с опытом технической проверки начинает тянуть за нитки. И под поверхностью открывается совсем другая история: захардкоженные секреты, логика аутентификации, рассчитанная только на корректные входные данные, зависимости, не обновлявшиеся с момента первого подключения. И бизнес-логика разбросана по файлам без какого-либо явного владельца.
Команды, которые строили эти продукты, были сосредоточены, и вполне оправданно, на выходе на рынок. Проблема в том, что высокоскоростная генерация кода с помощью ИИ производит особый тип технического долга: он накапливается быстрее, чем в коде, написанном людьми, потому что скорость генерации давно обогнала пропускную способность проверки. И это не проблема, характерная только для фаундеров-одиночек. Как написал один технический руководитель на Habr:
Скорость генерации давно обогнала скорость человеческой проверки. Один техлид не может спокойно прочитать почти две тысячи строк за полчаса и еще удержать в голове, что эти изменения ломают в соседних модулях.
Если это справедливо для команд с выделенным техническим руководством, то для двух основателей, разрабатывающих продукт с помощью ИИ, этот разрыв несравнимо больше.
Что инвесторы находят, когда смотрят под капот
Техническая проверка перед Series A – это процесс, специально нацеленный на то, чтобы выявить вещи, которые фаундеры сами не знают, что нужно подсветить. И все чаще те, кто эту проверку проводит, хорошо понимают, как выглядит код, сгенерированный ИИ, и где в нём обычно прячутся слабые места.
Выводы, которые срывают или затягивают сделку, редко бывают драматичными. Это никогда не звучит, как "продукт фундаментально сломан", а скорее предоставляют набор мелких проблем, которые в совокупности показывают: кодовая база строилась под скорость, а не под устойчивость. И некоторые категории всплывают почти всегда:
- Уязвимости безопасности, которые не были осознанным архитектурным решением. Ключи API, случайно оставленные в файлах под версионным контролем; отсутствие валидации входных данных на эндпойнтах, работающих с пользовательскими данными; сценарии аутентификации, которые корректно работают в штатном режиме, но ломаются в ситуациях, которые злоумышленник будет намеренно провоцировать. При быстрой генерации кода такие дыры возникают почти неизбежно, а без системных проверок их обычно находят слишком поздно.
- Архитектура, которая не масштабируется без переписывания. ИИ-генерация склонна решать задачу здесь и сейчас, а не вписывать код в общий дизайн системы. В итоге получается работающий продукт, который потребует существенного рефакторинга, прежде чем справится с нагрузкой в десять раз выше текущей. А это серьезная проблема для любого инвестора, чей фокус держится на росте.
- Риски зависимостей. Устаревшие пакеты, непроверенные транзитивные зависимости и лицензии, которые создают юридические сложности для корпоративных клиентов или потенциальных покупателей. Это наиболее незаметная в повседневной работе категория, и наиболее надежно всплывающая при технической проверке.
- Тестовое покрытие, которое проверяет только основной сценарий. ИИ генерирует тесты с той же скоростью, что и код – звучит хорошо, пока не понимаешь, что сгенерированные тесты проверяют сгенерированный код, а не реальные условия, с которыми он столкнется. Процент покрытия может выглядеть нормально, но покрытие сбоев и ошибок – слабое.
На эту тему один из инженеров на Hacker News написал:
Через полчаса после публикации изменений я получил письмо и сообщение от GitHub, что я раскрыл учетные данные. Я зашел в AWS и увидел, что они уже приостановили сервис – потому что процент недоставленных писем по 80 000 сообщениям, отправленным за те 15 минут, был слишком высоким. Просто безумие, как быстро это было использовано.
Вот насколько коротким бывает промежуток между коммитом и инцидентом.
И общий мотив во всех перечисленных категориях такой: по отдельности ни одна из этих проблем не является стоп-фактором. Но вместе они рассказывают опытному техническому проверяющему историю о кодовой базе, которую никогда системно не ревьюили. И это сразу становится аргументом на переговорах по условиям сделки: позволяет давить, требовать уступок или паузы на исправления. Иногда этого хватает, чтобы сделка вообще не состоялась.
Проблема подхода "мы исправим это перед раундом"
Логика "доработаем качество кода перед фандрайзингом" понятна, но она часто строится на неверной оценке объема работ.
Исправление уязвимостей и архитектурных проблем в уже работающей кодовой базе начинается с того, что эти проблемы нужно сначала полностью обнаружить – а в проекте, который генерировался на скорости без системного ревью, это само по себе задание непростое. Дальше их нужно исправить так, чтобы не сломать то, что уже работает. В продакшн-системе с реальными пользователями это задача с жесткими ограничениями, которая может занять недели сфокусированной инженерной работы.
Опытные разработчики, наследующие такие проекты, говорят об этом прямо:
Это будет намного сложнее, чем кажется... Исправление дизайна и/или архитектуры на высоком уровне обычно требует существенного переписывания, иногда даже смены технологического стека.
Это не короткий спринт перед раундом. Это многомесячный инженерный проект, который нужно вести параллельно со сбором инвестиций.
Подход "исправим все накануне" создает и проблему с выбором момента. Сроки технической проверки редко совпадают с вашим расписанием: инвестор может попросить ускориться через три недели, стратегический партнер может прислать техническую команду, дав вам десять дней на подготовку. Чаще всего необходимость привести код в порядок возникает не тогда, когда вам удобно, а тогда, когда это внезапно понадобилось другой стороне.
Есть и более фундаментальная проблема: разовая подготовка перед конкретным событием дает кодовую базу, которая была чистой однажды, а не ту, которая остается чистой. Если ИИ-ассистированная разработка продолжается (а у большинства команд, работающих с вайб-кодингом, она продолжается), новые проблемы вносятся постоянно. Предраундовое наведение порядка без постоянного слоя качества – временное решение структурной проблемы.
Что такое "санитарный слой" на практике
Концепция “санитарного слоя” проста: добавить постоянный автоматизированный слой, который непрерывно сканирует кодовую базу, выявляет проблемы и поднимает их на поверхность для устранения. Другими словами, работа происходит в фоновом режиме, пока команда занимается продуктом.
Одна из самых частых ловушек в этой логике – кажущаяся простота. Один комментарий на Hacker News точно передал иронию плана "просто обезопасим API":
Переписывание, скорее всего, окажется проще, потому что экраны и логика уже готовы. Большую часть нужно просто перенести на строгий бэкенд и правильно обезопасить API.
Ответ:
Как нарисовать сову: Шаг 1. Нарисуй круг. Шаг 2. Нарисуй остальное.
И вот "санитарный слой" существует именно для того, чтобы к нужному моменту на месте был не только круг.
На практике полноценный "санитарный слой" покрывает несколько конкретных категорий:
- Сканирование безопасности. Непрерывное выявление раскрытых утечек, уязвимых зависимостей, отсутствующей валидации входных данных и пробелов в аутентификации – не как разовый аудит, а как текущий процесс, который отмечает новые проблемы по мере их появления.
- Контроль качества и согласованности кода. Проверка сгенерированного кода на соответствие стандартам и паттернам конкретной команды, а не "лучшим практикам". Разница принципиальная: когда система подсвечивает нарушение ваших собственных соглашений, это сразу понятно и исправимо. Когда она сравнивает код с абстрактным эталоном, замечания часто оказываются спорными и плохо применимыми.
- Мониторинг зависимостей. Регулярно проверяет все зависимости (включая косвенные) на обновления, уязвимости и изменения лицензий, которые могут создать риски для корпоративных контрактов или при покупках компании/продукта.
- Мониторинг тестового покрытия. Сгенерированные тесты склонны проверять сгенерированный код, а не условия, которые реально его сломают. Процент покрытия не гарантирует качество: критичные сбои и нетипичные запросы часто остаются непроверенными. Этот разрыв – источник производственных инцидентов и первое место, куда смотрит проверяющий при технической проверке, когда хочет понять: команда тестирует реальность или просто закрывает метрику.
Ценность "санитарного слоя" в постоянных задокументированных свидетельствах того, что кодовая база активно поддерживается.Именно на это и смотрит технический проверяющий, чтобы понять: у команды есть инженерная дисциплина – или только скорость разработки?
Как Enji Guard работает без штатного специалиста по безопасности
Enji Guard – это наш прямой ответ на описанную выше проблему. Исходная идея была простой: на ранних этапах у большинства команд, которые активно используют генерацию кода, нет штатного инженера по безопасности, выделенной QA-функции или техлида с ресурсом на непрерывное ревью. Им нужен механизм, который автоматически делает эту непрерывную работу и выводит результаты в таком виде, чтобы по ним можно было действовать без глубокой технической экспертизы.
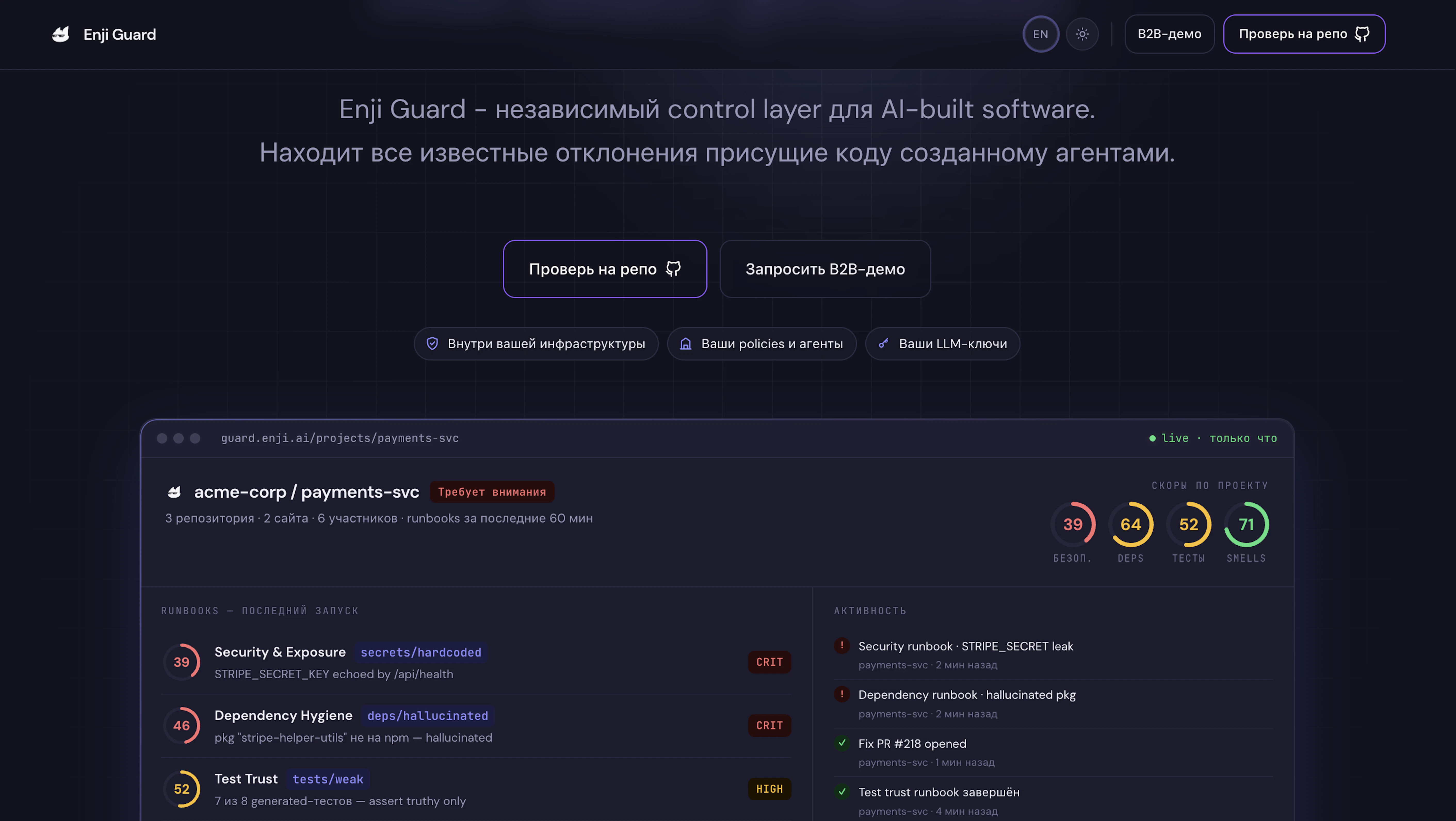
Речь не о вере или неверии в ИИ, а о темпе: генерация быстрее проверки, значит, проверки должны идти непрерывно. Именно так на это смотрят самые практичные техлиды. Как описал свой подход один технический руководитель на Habr:
Я пошел не в сторону запретов, а в сторону страховки. Обвязал ИИ-ассистента конвейером. Каждый коммит проходит автоматический анализ. Каждый запрос на слияние получает оценку риска и радиус изменений. Я не доверяю генератору кода без автоматической проверки. И себе, если честно, тоже.
Guard – это именно такой конвейер, созданный для команд, у которых нет внутреннего ресурса строить его самостоятельно. С точки зрения моделей Guard работает с ведущими ИИ-решениями, как Claude, Codex, Kimi, с расширением поддержки в плане развития. Один практический момент, который стоит назвать прямо: Guard работает на существующих ИИ-подписках команды. Никаких отдельных API-ключей, никакого дополнительного лицензирования на пользователя, никакой привязки к одному провайдеру моделей. Для стартапа на ранней стадии это способ усилить качество и безопасность без расширения бюджета.
Архитектурное отличие Guard от разовой проверки кода с помощью ИИ в том, что Guard никогда не останавливается. После запуска он сканирует непрерывно и уведомляет при появлении проблем. Это практическая разница между тем, чтобы поймать проблему в день ее появления, и тем, чтобы поймать ее три месяца спустя – уже в производственной среде и, возможно, уже обнаруженную кем-то другим.
Что делает Guard полезным на практике – это наборы инструкций. В отличие от типичных ИИ-советов по "лучшим практикам", они фиксируют правила именно вашей команды: архитектуру, паттерны и соглашения. Поэтому система может проверять пул-реквесты, искать уязвимости и следить за единообразием так, как принято у вас.
Есть и важное техническое преимущество, которое легко не заметить: когда работа разбита на отдельные, узко сфокусированные прогоны по инструкции, результат обычно лучше, чем в одном длинном запуске агента. В длинных сессиях контекст начинает «перетекать»: ранние выводы и формулировки незаметно влияют на последующие решения и снижают точность. Раздельные инструкции под конкретные задачи эту проблему убирают.
Поэтому ценность таких инструкций двойная. Технологическая часть (несколько агентов, непрерывная проверка, работа по подписке) – это база. Но реальное отличие – в самих инструкциях. Плохо составленная инструкция ничем не лучше случайного промпта из интернета. Хорошая отражает инженерное понимание того, что действительно важно именно в этой кодовой базе – и это понимание команда Guard приносит в проект напрямую.
Guard делает результаты понятными и для нетехнических фаундеров. Находки отсортированы по приоритету и объяснены простым языком: не сырой отчет об уязвимостях, для интерпретации которого нужен специалист по безопасности, а четкая картина того, что под угрозой, почему это важно и что нужно сделать. Именно такой формат делает санитарный слой пригодным к использованию для тех команд, для которых он создан.
Как кодовая база, собранная с помощью вайб-кодинга, становится готовой к инвестициям, и сколько это занимает
Честный ответ: зависит от того, как долго база накапливалась без систематической проверки и насколько интенсивно шла генерация. Но траектория достаточно стабильна, чтобы ее описать.
Первые две-четыре недели после запуска Guard – самые интенсивные: это фаза первоначального сканирования, когда на поверхность всплывает накопленный список существующих проблем. Для кодовой базы, которая 6-12 месяцев год активно разрабатывалась с ИИ без систематической проверки, первичные находки, как правило, существенны: обнаружены утечки, уязвимые зависимости, архитектурные несоответствия, пробелы в тестировании. На этом же этапе становится ясна общая картина: проблем чаще больше, чем ожидали фаундеры, но исправлять их обычно проще, чем они кажется.
Следующие 4-8 недель – фаза устранения. Guard продолжает сканировать, пока команда закрывает приоритетные пункты. Инструкции уточняются по ходу – под то, что где проблема реально находится, и под то, как команда хочет это исправлять. Кодовая база постепенно переходит в состояние, где технический проверяющий видит признаки системного обслуживания, а не накопленного запущения.
К третьему месяцу у команд с относительно небольшим проектом обычно появляется нормальный режим: новые проблемы находят и закрывают быстро – за несколько дней, а не спустя месяцы. Если кодовая база росла 6-12 месяцев без системного контроля, на выход в такой режим уйдет больше времени. Но логика не меняется: код не станет идеальным, зато станет заметно более чистым и защищаемым – и это будет видно любому техническому проверяющему.
Именно поэтому срок запуска критичен. Если фаундер планирует Series A через 6-9 месяцев, запустить санитарный слой сейчас, а не за три месяца до раунда, дает принципиально лучший результат. Работа по устранению распределяется на более длинный период, состояние базы в момент технической проверки стабильнее, и фаундер может отвечать на вопросы о качестве кода с опорой на данные, а не на обещания.
Что говорить инвестору, когда он спрашивает о качестве кода
Этот вопрос возникает почти в каждом разговоре о технической проверке и приходит в разных формах: "Как вы управляете техническим долгом?", "Как выглядит ваш процесс проверки кода?", "Как вы решаете вопросы безопасности?" Но подлинный вопрос всегда один: у команды есть инженерная дисциплина, или они просто быстро разрабатывали и надеялись на лучшее?
Худший ответ – размытое заверение. "Мы серьезно относимся к качеству" или "у нас хорошие инженерные практики" – это утверждения, которые технический проверяющий немедленно захочет верифицировать. И если верификация их не подтвердит, ущерб для доверия окажется больше, чем если бы вы вообще ничего не сказали.
Лучший ответ – конкретный и задокументированный. "Мы запускаем непрерывное автоматизированное сканирование через Guard, которое формирует приоритизированный список проблем, разбираемый на регулярной основе. Вот текущее состояние уязвимостей в наших зависимостях. Вот наше покрытие аутентификации и валидации входных данных. Вот как выглядит наш процесс проверки запросов на слияние". Такой ответ демонстрирует и то, что команда понимает, что делает, и то, что у нее есть инфраструктура, чтобы продолжать делать это в масштабе.
Санитарный слой – это доказательная база для разговора, который каждый серьезный инвестор захочет провести. Фаундеры, у которых эта база есть к моменту технической проверки, могут вести разговор на своих условиях, и именно это отличает убедительный ответ от общих обещаний.
Скорость, которая привела вас сюда, – это актив. Сделать так, чтобы она не стала риском в самый важный момент – решаемая задача. Начало простое: подключите Guard к репозиторию, запустите первичное сканирование и посмотрите, что там есть на самом деле.