Вводная: какую задачу мы решали
Эта статья не про "как выбрать модель", а про то, как мы шаг за шагом пришли к мультиагентной системе, которая помогает разворачивать фичи в продукте от начала до конца с ИИ из нескольких репозиториев.
Исходная задача была приземленная: масштабировать разработку в нескольких репозиториях, не утопив команду в контекстах, регламентах и ручной синхронизации.
Боль: несколько репозиториев, рутина и ручная координация
С чем мы столкнулись на старте:
- Несколько репозиториев в одном продукте.
- Одни и те же шаги при старте любой фичи.
- Ручная синхронизация между кодом, спеками и договоренностями.
- Тяжелые ревью, особенно когда изменения затрагивают несколько компонентов.
На этом этапе про ИИ вообще речи не было. Нас интересовало только одно: как уменьшить количество рутинных решений, которые разработчик принимает каждый день.
Первый шаг: обычная инженерная автоматизация
Что мы сделали вначале:
- Скрипты для генерации шаблонов и бойлерплейта.
- Единую структура фич в разных репозиториях.
- Утилиты для навигации: быстро понять, где что лежит, куда добавлять код.
- Автоматизацию типовых шагов перед PR: проверки, форматирование, подготовка описания.
Фактически мы описали в скриптах ответ на вопросы:
"Как у нас правильно заводить фичу?" "Как правильно разнести изменения по сервисам?" "Как подготовить PR так, чтобы его можно было быстро ревьюить?"
Важно: задним числом стало понятно, что эти скрипты – это уже зашитая политика поведения. Там были правила и ограничения, просто без LLM.
Второй шаг: LLM как интерфейс к этим правилам
Когда стали доступны LLM-инструменты, мы не начали с "автокомплита всего и вся". Вместо этого мы сделали модель интерфейсом к нашей автоматизации и стайлгайдам, а не "умной чёрной коробкой", которая всё решает сама.
Ключевые принципы:
- Источник истины – код и конфиги, а не ответы модели.
- Архитектурные решения и ограничения зафиксированы заранее.
- LLM работает только в заданных рамках и запускает нужные сценарии.
На практике это выглядело так:
- Разработчик описывает интент (что он хочет сделать) →
- Агент понимает контекст проекта (репозитории, сервисы, архитектуру) →
- Затем агент дергает нужные скрипты/паттерны, а не "придумывает мир с нуля"
Для команды это ощущается не как "ИИ-магия", а как удобный слой поверх знакомых процессов.
Естественный переход к мультиагентности
По мере роста сценариев один "универсальный" агент начал терять управляемость. Он одновременно пытался планировать, принимать архитектурные решения, писать код в разных доменах и проверять результат. Возникла классическая проблема "бога-объекта", только в форме ИИ-агента.
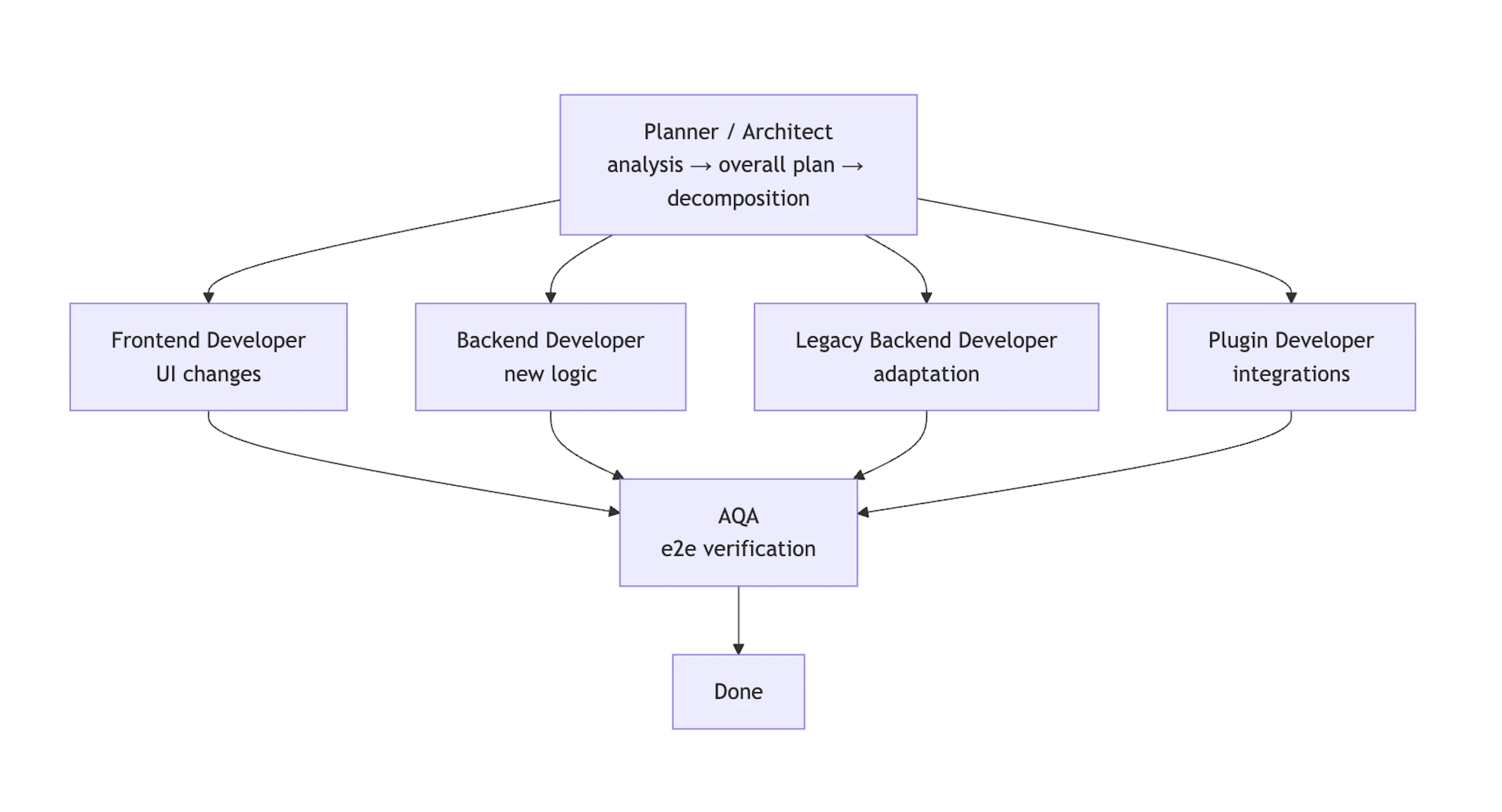
Логичным шагом стало разнесение ответственности: не по абстрактным ролям, а по отдельным исполняемым агентам, каждый из которых запускается в своем контексте и работает независимо. У нас появились специализированные агенты для следующих областей:
Планирование и архитектура
Планер / Архитектор – формирует согласованный план изменений по всем затронутым репозиториям, определяет границы, контракты и порядок внедрения.
Разработка
- Frontend-разработчик – изменения UI и клиентской логики.
- Backend-разработчик – основной серверный код.
- Bbackend-разработчик с уклоном в legacy – адаптация существующих старых сервисов.
- Разработчик плагинов – интеграции, расширения, внешние точки подключения
Качество
AQA – пишет и поддерживает e2e-тесты, проверяет поведенческие инварианты системы.
Что в итоге: почти полноцикловая реализация фичи
В итоге каждый агент отвечает за определенный этап рабочего процесса, и весь цикл — от архитектурного проектирования до окончательной проверки — превращается в практически сквозную реализацию функционала с минимальным участием человека.