Тема большая, поэтому здесь я постараюсь дать общее представление о том, как подходить к задаче перехода с мощных облачных моделей на локальные — менее производительные, но доступные для развёртывания внутри закрытого периметра.
Допустим, вы построили агентный пайплайн для корпоративной автоматизации на базе моделей от Google и OpenAI. Например, корпоративный чат-бот, который отвечает на вопросы о проектах компании, загрузке сотрудников и умеет принимать и выполнять задачи в соответствии с заданными правилами.
Все работает до момента, когда компания сообщает, что из-за регуляторных требований вы больше не можете использовать внешние модели и обращаться к API через интернет. Локальный облачный провайдер топовые модели пока не предоставляет. Единственный выход — переписать пайплайн под опенсорсные локальные модели, которые можно запустить на собственном железе. Допустим, в вашем распоряжении 10 карт RTX 4090.
Ниже — минимальный базовый мануал для тех, кто встает на этот путь.
Выбор одной или нескольких моделей для пайплайна
На рынке много опенсорсных моделей, которые по бенчмаркам приближаются к SOTA прошлого поколения (Claude Sonnet 3.5, GPT-4o) и при этом доступны для локального запуска. Однако модели, которые сегодня реально дотягиваются до этих показателей — Kimi 2, Minimax M2.1, GLM-4.7 — требуют настолько большого количества GPU, что получить под них ресурсы внутри компании крайне сложно.
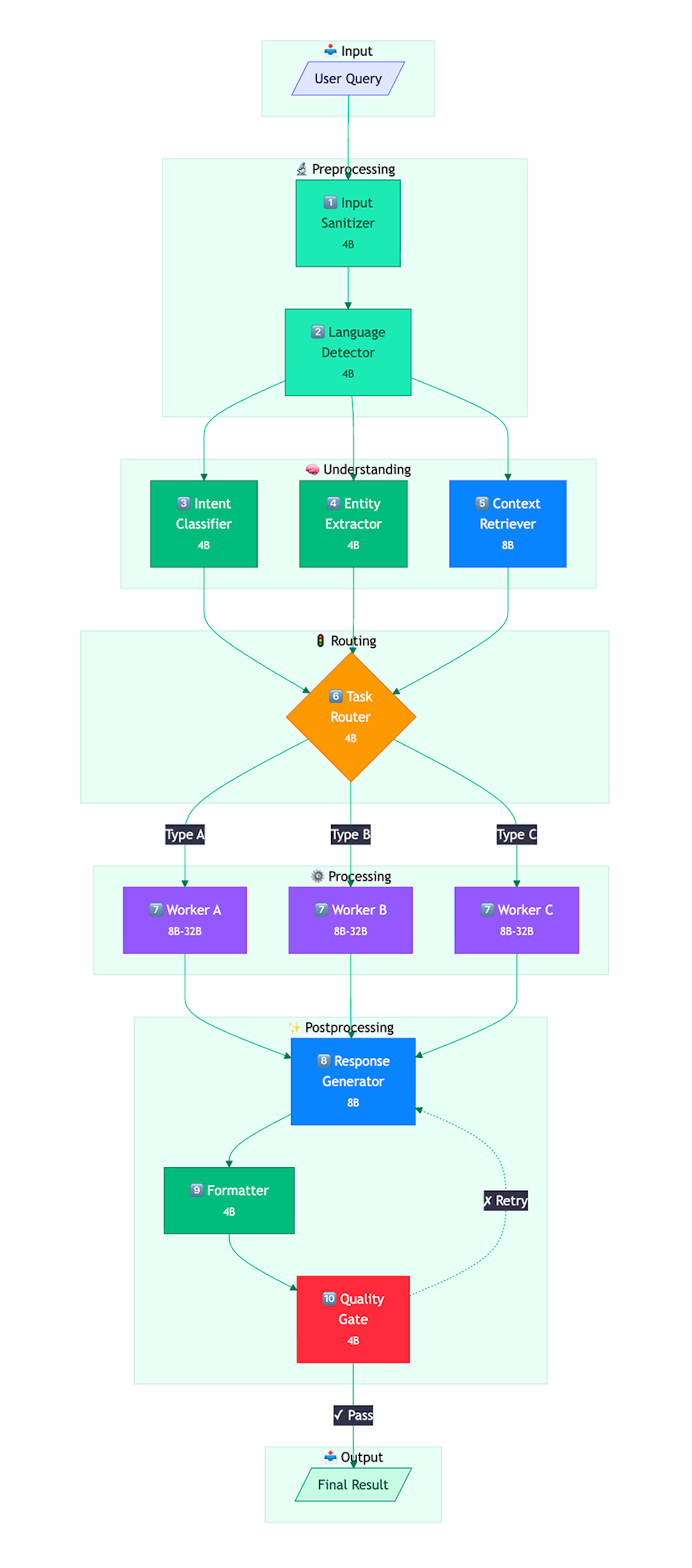
Поэтому приходится смотреть в сторону моделей поменьше. После долгих экспериментов наша команда остановилась на семействе Qwen3 в трех вариантах: 4B, 8B и 32B (у 32B есть режим рассуждений для сложных задач). Разные узлы пайплайна обслуживают разные модели в зависимости от сложности задачи. Если узел справляется с 4B параметрами, нет смысла гонять 32B: меньше потребление электроэнергии, меньше нагрузка на железо, больше возможностей для параллельных вычислений.
Дробление пайплайна на узлы
Чем умнее модель, тем шире промпт, с которым она справляется: можно давать более объемный контекст и рассчитывать на то, что модель сама верно интерпретирует намерение пользователя. При переходе на менее мощные OSS-модели первое, что нужно сделать, — разбить пайплайн на максимально возможное количество небольших специализированных узлов.
Вот упрощенная схема пайплайна, который хорошо работает с мощными SOTA-моделями уровня Claude Opus 4.5 или Gemini 3 Pro High: