Управление данными: Ключевые термины
Что такое целостность данных
Что такое целостность данных
Целостность данных — это точность, согласованность и надежность данных на протяжении всего их жизненного цикла: с момента создания или сбора до хранения, передачи и использования. Это означает, что данные остаются неизменными, полными и достоверными, если только они не были изменены в ходе авторизованного и намеренного процесса.
Для инженерных и команд поставки целостность данных — это разница между отчетом о статусе проекта, отражающим реальность, и отчетом, отражающим ее искаженную версию. Когда ворклоги отсутствуют, статусы задач устарели, а финансовые данные не сходятся между инструментами, каждое решение, основанное на таких данных, несет в себе скрытый риск. Именно высокая целостность данных делает метрики, отчеты и инсайты на основе ИИ по-настоящему пригодными для принятия решений, а не просто правдоподобно выглядящими.
Целостность данных и качество данных: в чем разница?
Эти два термина нередко используются как синонимы, однако они описывают разные проблемы.
- Качество данных — это то, насколько хорошо данные служат своей цели в конкретный момент. Оно охватывает такие измерения, как точность, полнота, релевантность и актуальность, и отвечает на вопрос: пригодны ли данные для использования прямо сейчас.
- Целостность данных — это то, остаются ли данные корректными, согласованными и достоверными со временем и в разных системах. Она фокусируется на сохранении корректности по мере того, как данные проходят через процессы, интеграции и слои хранения, и учитывает риски: сбои систем, несанкционированные изменения, проблемы синхронизации и ошибочная логика преобразования между инструментами — причем нередко без видимых ошибок.
Если кратко: качество данных — это то, что вносится; целостность данных — это то, что сохраняется в процессе. Качество может деградировать из-за ошибок ввода или устаревших записей, тогда как целостность может быть нарушена сбоями систем, несанкционированными изменениями, проблемами синхронизации или ошибочной логикой преобразования между инструментами.
Практический пример: запись в ворклоге может быть точной в момент создания (хорошее качество данных в конкретный момент), но стать несогласованной, если она дублируется при миграции доски в Jira и дубликат не замечают — это уже нарушение целостности данных. Оба аспекта важны, но требуют разных мер защиты.
→ Качество данных — это то, что вносится.
→ Целостность данных — это то, что сохраняется в процессе.
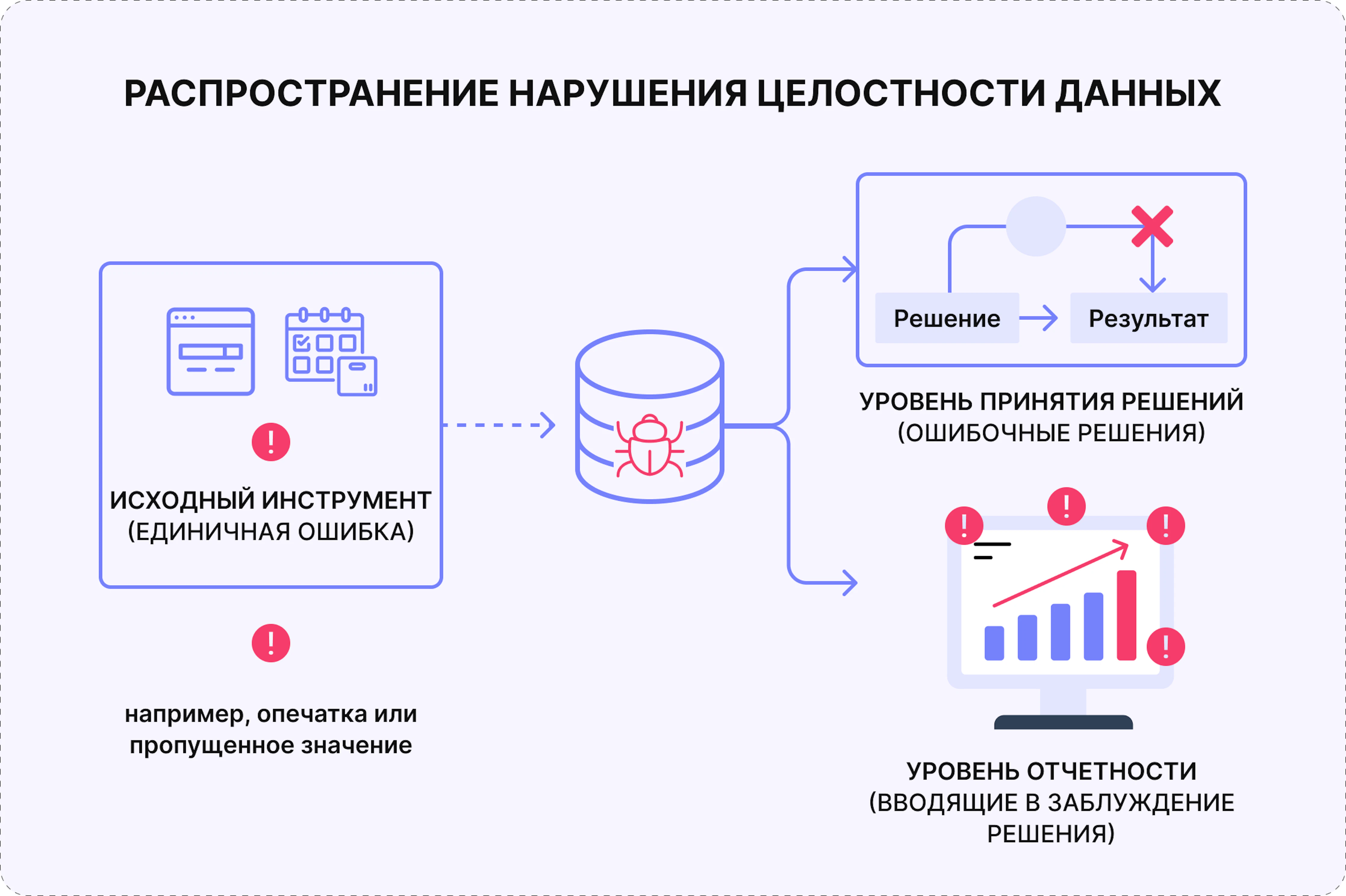
Почему целостность данных важна
Когда целостность данных нарушается, последствия расходятся кругами от точки сбоя: задублированная запись задачи завышает отчетные часы, пропущенная синхронизация создает несуществующее расхождение в затратах, а некорректное обновление статуса делает завершенную функцию заблокированной. Каждый из этих случаев кажется незначительным в отдельности — но, накапливаясь в рамках проекта или портфеля, они системно подрывают качество решений, принимаемых на основе данных.
Для инженерных команд в разных отраслях целостность данных важна сразу в нескольких взаимосвязанных измерениях.
- Достоверная отчетность. Финансовые отчеты, метрики поставки и анализ мощностей настолько достоверны, насколько достоверны питающие их данные. Нарушения целостности порождают отчеты, которые выглядят корректно, но вводят в заблуждение.
- Точность ИИ и автоматизации. ИИ-инструменты, генерирующие сводки, выявляющие риски или отвечающие на вопросы о проекте, полностью зависят от согласованности данных из источников, к которым они обращаются. Несогласованные данные порождают уверенно звучащие, но ошибочные результаты.
- Аудит и соответствие требованиям. В регулируемых отраслях и для корпоративных клиентов доказуемая целостность данных нередко является договорным или нормативным требованием, а не просто операционным предпочтением.
- Доверие между командами. Когда инженеры, менеджеры и финансовые руководители работают с разными версиями одних и тех же данных, согласованность разрушается. Именно целостность данных делает единый источник истины действительно единым.
Целостность данных — это фундамент для любой другой практики работы с данными в организации. Без нее метрики качества, дашборды производительности и инсайты ИИ стоят на нестабильной почве.
Как обеспечить и поддерживать целостность данных?
Поддержание целостности данных — это непрерывная операционная дисциплина, а не единовременная настройка. Ключевые практики укладываются в несколько последовательных категорий.
- Валидация на входе. Наиболее экономически эффективное место для выявления проблем с целостностью — до того, как они распространятся. Правила валидации, помечающие аномалии (дублирующиеся записи, значения вне допустимого диапазона, отсутствующие обязательные поля), предотвращают попадание ошибок в систему, а не обнаруживают их позже по цепочке.
- Контролируемый доступ и управление изменениями. Целостность данных требует знания о том, кто и что может изменить, а также наличия журнала аудита: что изменилось, когда и почему. Неограниченный доступ к редактированию в общих источниках данных — один из наиболее распространенных источников нарушений целостности в командных средах.
- Согласованная логика интеграции. Когда данные перемещаются между инструментами — из Jira в отчетную платформу, из системы учета времени в финансовую систему — логика преобразования должна применяться единообразно. Несовпадающее сопоставление полей, частичные синхронизации и конфликты версий между интеграциями — это там, где целостность чаще всего нарушается в многоинструментных средах.
- Регулярная сверка. Периодические проверки, сравнивающие данные в подключенных системах, верифицируют соответствие итогов, согласованность записей и отсутствие неожиданных дубликатов или пробелов. В активных средах поставки еженедельная сверка ключевых показателей — разумный минимум.
- Резервное копирование и процедуры восстановления. Целостность данных включает защиту от потери или повреждения на уровне хранилища. Регулярные резервные копии с проверенными процедурами восстановления гарантируют возможность восстановления целостности даже после сбоев системы.
Обеспечение и поддержание целостности данных требует продуманного проектирования, последовательного соблюдения требований и постоянного внимания по мере эволюции систем, команд и процессов. Само по себе это не поддерживается.
Что такое инструменты целостности данных и как помогает Enji?
Инструменты целостности данных — это системы или функции платформ, которые обеспечивают, мониторят и восстанавливают согласованность данных на протяжении всего жизненного цикла: от ограничений на уровне базы данных и правил валидации до мониторинга интеграций, журналов аудита и обнаружения аномалий.
Для организаций, управляющих данными в разных инструментах, проблема целостности сосредоточена прежде всего на границах между этими системами: при синхронизации, агрегации и преобразовании. Именно там происходит большинство сбоев и именно там специализированные инструменты дают наибольший эффект.
1. Устранение риска преобразования через нативные интеграции
🟣 Прямые API-подключения к Jira, GitHub, Slack и другим инструментам получают данные из источника, а не полагаются на ручной экспорт или промежуточные форматы. Когда Enji обнаруживает, что задача переместилась между досками или проектами (распространенный источник дублирования ворклогов), он обновляет ключ задачи и переносит все связанные записи вместо создания дубликатов, сохраняя ссылочную целостность набора данных.
2. Автоматическое заполнение пробелов в ворклогах
🟣 Для данных ворклогов, где пробелы и несоответствия особенно распространены, ворклоги обеспечивает автоматическую генерацию на основе реальных паттернов активности. Система применяет согласованную формулу для распределения времени по активным задачам, создавая полные и унифицированные записи без необходимости ручного ввода от каждого участника команды.
3. Выявление финансовых расхождений до их искажения отчетности
🟣 Маржинальность проектов поддерживает финансовый слой в режиме реального времени, непрерывно сверяя затраты на труд, счета подрядчиков и распределение бюджета с данными задач и спринтов. Когда появляются расхождения — например, разница между залогированными и выставленными к оплате часами — они всплывают как обнаруживаемые аномалии, а не как скрытые искажения, которые проявляются только когда отчет выглядит неправильно.
4. Гарантия того, что результаты ИИ отражают реальное состояние проекта
🟣 Результаты PM Агента настолько достоверны, насколько достоверны данные, из которых они формируются. Поддерживая целостность на уровне инфраструктуры, Enji гарантирует, что когда менеджер поставки задает вопрос о проекте, ответ отражает реальное состояние проекта, а не версию, собранную из несогласованных источников в разрозненных инструментах.
Главное по теме
- Целостность данных означает, что данные остаются точными, согласованными и достоверными на протяжении всего жизненного цикла — в отличие от качества данных, которое измеряет пригодность для использования в конкретный момент.
- Нарушения целостности распространяются незаметно: одна дублирующаяся запись или пропущенная синхронизация могут исказить отчеты и подорвать результаты ИИ, не вызывая видимой ошибки.
- Поддержание целостности требует валидации на входе, контролируемого доступа, согласованной логики интеграции, регулярной сверки и надежного резервного копирования.
- В многоинструментных средах наиболее рискованные точки находятся на границах систем: при синхронизации, агрегации и преобразовании.
- Enji защищает целостность данных поставки через нативные интеграции, автоматический перенос записей при реорганизации проекта, согласованную генерацию ворклогов и финансовую сверку в реальном времени.
- Надежная аналитика поставки зависит от целостности данных в основе — без нее каждый следующий слой, построенный сверху, менее надежен, чем кажется.

Последнее обновление: июль 2026 г.