What problem were we solving?
This article doesn't only focus on "how to choose the right model," but mostly on how we gradually built a multi-agent system that helps deploy features end-to-end across a multi-repository product.
The original problem was straightforward: scale development across multiple repositories without drowning the team in context-switching, process overhead, and manual synchronization.
The pain: multiple repositories, repetitive work, and manual coordination
Here's what we were dealing with from the start:
- Multiple repositories within a single product.
- The same repetitive steps are followed every time a new feature is kicked off.
- Manual synchronization between code, specs, and team agreements.
- Heavy code reviews, especially when changes touched multiple components.
At this stage, AI wasn't even on our radar. We had one goal: to reduce the number of routine decisions developers had to make every day.
First step: plain engineering automation
Here's what we did first:
- Scripts for generating templates and boilerplate.
- A unified feature structure across repositories.
- Navigation utilities to quickly understand where things lived and where to add new code.
- Automation of standard pre-PR steps: checks, formatting, description preparation.
Essentially, we encoded the answers to these questions in scripts:
"What's the right way to create a new feature here?" "How do we correctly distribute changes across services?" "How do we prepare a PR so it can be reviewed efficiently?"
In hindsight, we realized those scripts already embedded behavioral policies, rules, and constraints, just without an LLM.
Second step: LLM as an interface to those rules
When LLM-based tools became available, we didn't go all-in on "autocomplete everything." Instead, we made the model an interface to our existing automation and style guides, not a "smart black box" that figures everything out on its own.
Core principles:
- Source of truth = code and configs, not model responses.
- Architectural decisions and constraints are defined upfront.
- LLMs operate strictly within defined boundaries and trigger the right workflows.
In practice, it looked like this:
- The developer describes intent (what they want to do). →
- The agent understands the project context (repositories, services, architecture). →
- Agent calls the right scripts/patterns rather than "inventing the world from scratch."
For the team, this didn't feel like "AI magic." It felt like a convenient layer on top of familiar processes.
The natural evolution toward multi-agent architecture
As use cases grew, a single "universal" agent became unmanageable. It was simultaneously trying to plan, make architectural decisions, write code across different domains, and verify results. We'd hit the classic "god object" problem, just in the form of an AI agent.
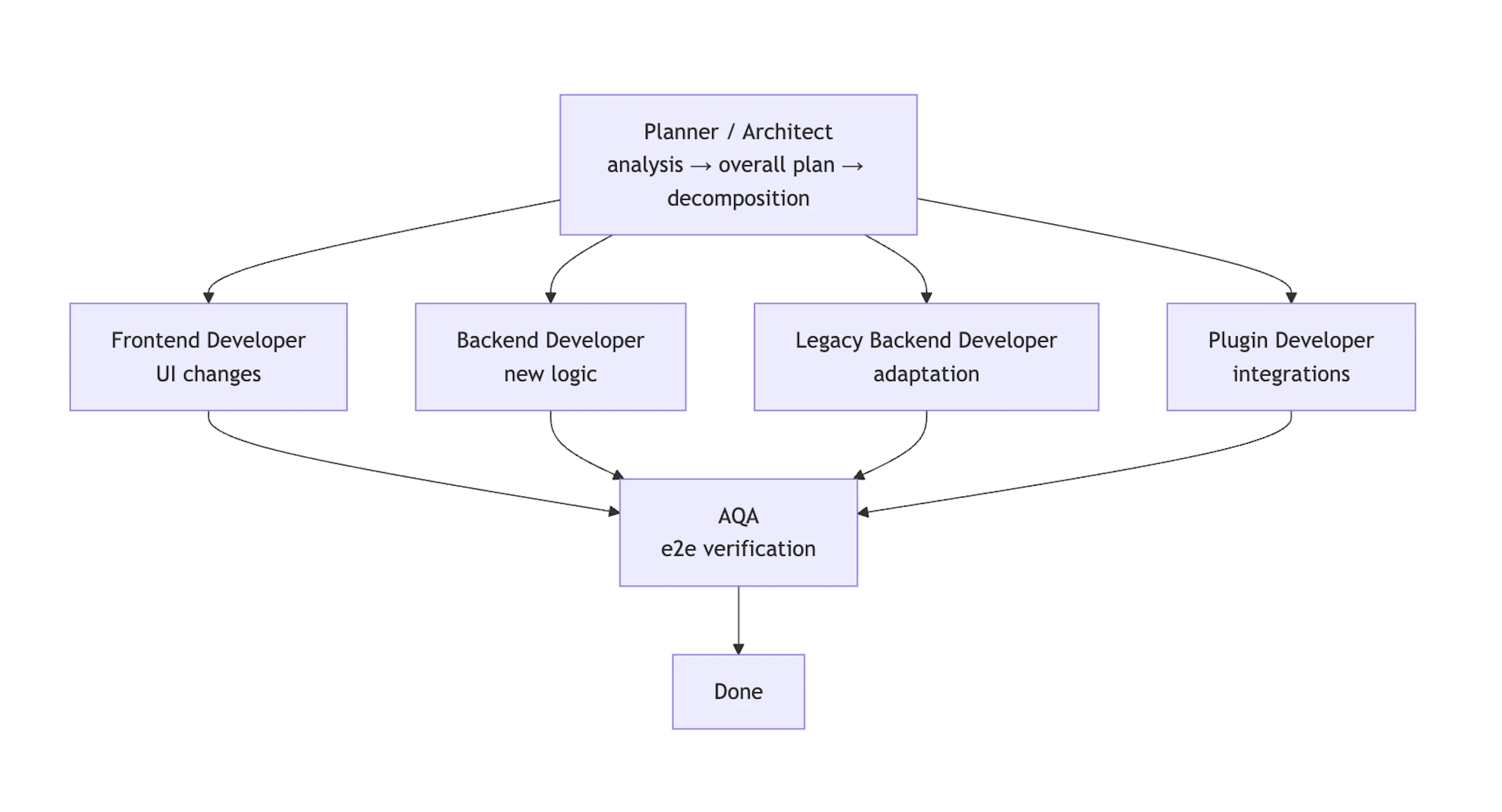
The logical move was to split responsibilities, not by abstract roles, but into separate execution agents, each running in its own context and operating independently. We ended up with specialized agents for:
Planning & architecture
Planner / Architect: builds a coherent plan of changes across all affected repositories and defines boundaries, contracts, and implementation order.
Development
- Frontend Developer: UI changes and client-side logic.
- Backend Developer: core server-side code.
- Legacy Backend Developer: adapts existing legacy services.
- Plugin Developer: integrations, extensions, external connection points.
Quality
AQA: writes and maintains e2e tests and verifies behavioral system invariants.
The outcome: near full-cycle feature implementation
In the end, each agent owns a specific part of the workflow, and the whole stream — from architectural planning to final verification — turns into an almost end‑to‑end feature implementation with minimal human involvement.