The problem with asking people for status
I've been a project manager long enough to know that the weekly status meeting is one of the most expensive habits in engineering organizations and one of the hardest to question because it feels productive while it's happening.
Here's what a typical status meeting actually costs: six people in a room for an hour, one person prepared, three people summarizing work they already reported in standup, one person waiting to ask a question that could have been a message. Plus, one manager synthesizing it all in real time, under social pressure, trying to form a coherent picture of project health from six different accounts delivered at different levels of detail.
By the time the meeting ends, the manager has a rough mental model. It starts degrading the moment they leave the room; when they need to update a stakeholder, they're working from memory, notes that are already two days old, and whatever Jira tells them, which is rarely the full story.
The information people want from a status meeting is legitimate. The format for getting it is what's broken.
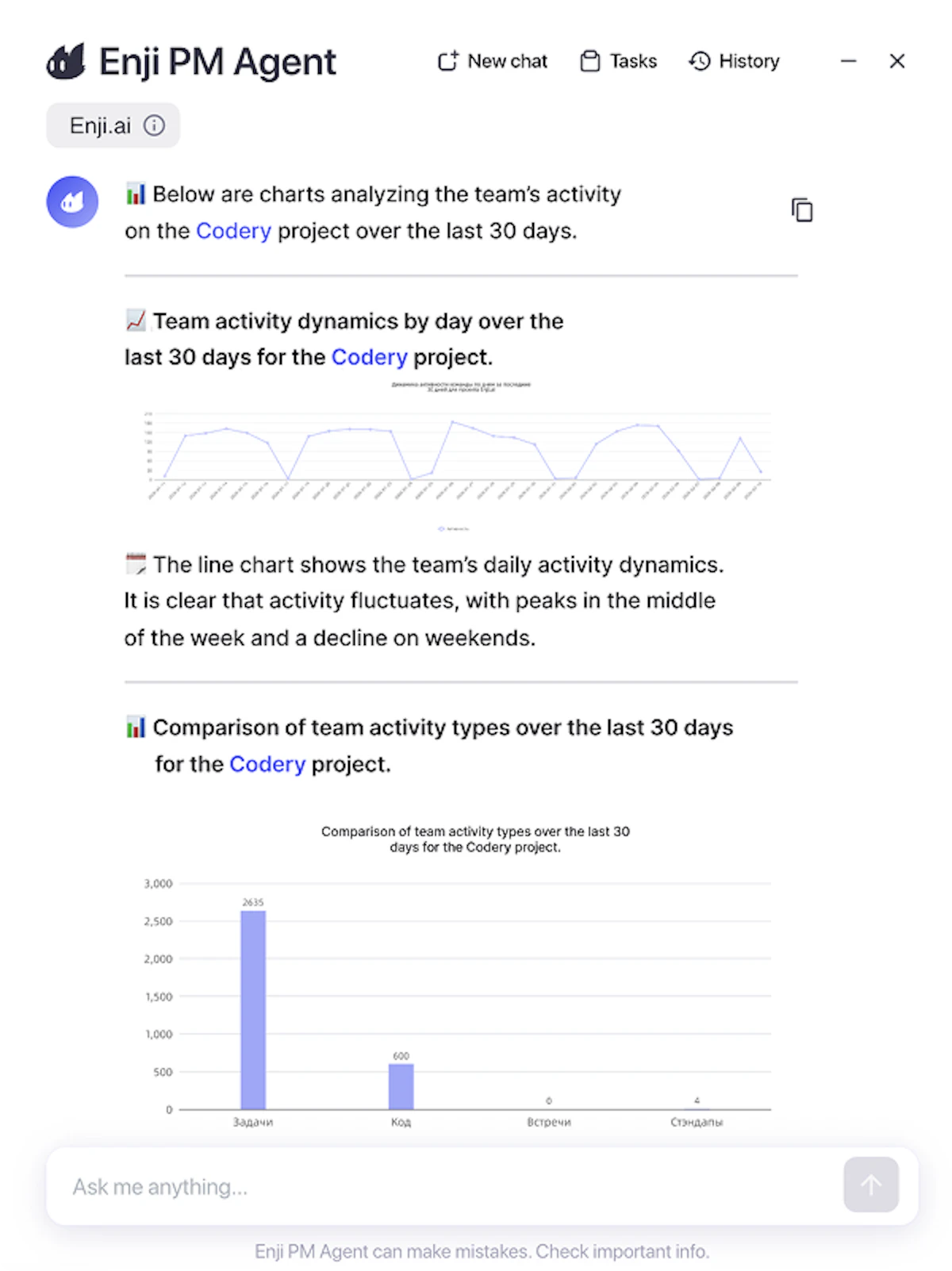
Status meetings vs. status queries: same information, different cost
What does a status meeting actually produce? If you strip away the social dynamics and the scheduling overhead, you're usually trying to answer five questions:
- What was completed this week?
- What's blocked, and why?
- Are we on track against the milestone?
- Are there any risks the team hasn't escalated?
- What does the team need from me to keep moving?
These are answerable questions. They have sources: task trackers, commit history, standup logs, worklog data, and calendar data. The information exists. The meeting is, functionally, a manual process for aggregating it, one that scales poorly, degrades in accuracy under time pressure, and depends entirely on whether the right people showed up and remembered to mention the right things.
A status query to PM Agent 3.0 answers the same five questions from the same underlying sources, without scheduling a meeting, without pulling six people out of focus time, and without the information starting to expire the moment it's delivered.
The cost difference is significant. In my experience, the agent consistently surfaces blockers that weren't mentioned in the meeting because they were in the ticket data, not in anyone's memory.